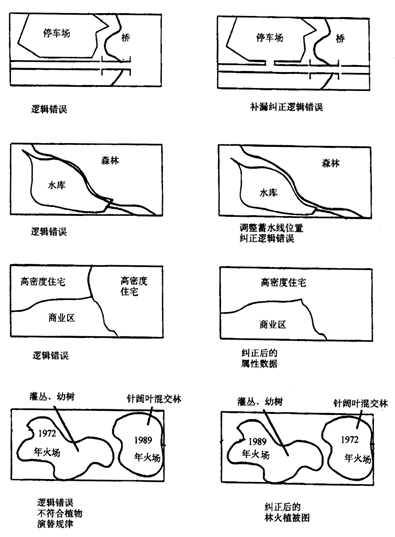
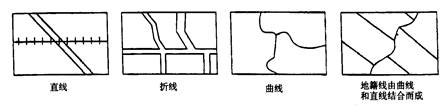
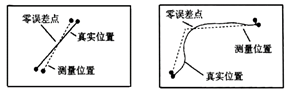
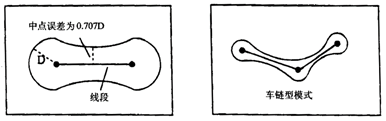
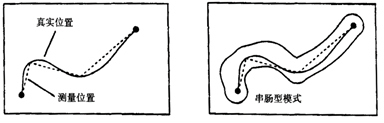
GIS is an integrated system based on computer software, hardware and data, the system mainly achieves spatial retrieval, editing and analysis through the operation of spatial and non-spatial data. Data is one of the most important factors in GIS. After the selection of computer software and hardware environment, the quality of data in GIS determines the quality of system analysis and the success or failure of the whole application. The analytical methods of spatial data provided by GIS are widely used in various fields, and the quality requirements for data in decision-making fields should be known or predictable. That is, the proximity between a recorded value (measured or observed value) and its true value. This concept is quite abstract, as if people already know the existence of such a fact. In practice, knowledge of measurement may depend on the type and scale of measurement. Generally speaking, the accuracy of individual observations or measurements is evaluated only by comparing them with the most accurate measurements available or recognized classification. The accuracy of spatial data is often categorized by location, topology or non-spatial attributes. It can be measured by error. That is, the level of detail of the phenomenon description, for the same two points, data with low precision is not necessarily accurate. Accuracy requires measurements to be recorded with the best accuracy, but this can be misleading to provide greater accuracy because numbers that exceed the known accuracy of a measuring instrument are cumbersome in efficiency. Therefore, if the coordinates returned by a manually operated digitizer cannot be dependent on a “true” value that is more accurate than 0.1 mm, then there is no point, expressed in mm in one tenth place. Resolution is the smallest detectable difference between two measurable values. Thus, spatial resolution can be viewed as the minimum distance required to record a change. On a map legible to the naked eye, assuming a line is used to represent a boundary, resolution is typically determined by the narrowest possible line width. Map lines are rarely drawn with a width of less than 0.1 mm. In a graphic scanner, the finest physical resolution is theoretically determined by the separation between the device’s pixels. On a laser printer, this measures 1/300th of an inch, while high-quality laser scanners can refine this precision tenfold. Without magnification, the finest lines produced by such scanners remain invisible to the eye, though this also depends on the contrast with the background color. Therefore, a discrepancy exists between human visual resolution and the physical resolution of devices. A similar distinction can be observed between the minimum distance discernible by a human operator using a digitizer and the minimum distance that the digitizer hardware can consistently record. A scale is a ratio between the distance of a record on a map and the “real world” distance it represents. The scale of the map will determine the distance from the ground represented by the width of a line on the map. For example, on a 1:10000 scale map, a 0.5mm wide line corresponds to a 5m ground distance. If this is the minimum width of the line, then it is impossible to represent a phenomenon less than 5m. After defining the accuracy between a recorded measurement and its facts, it is clear that for most purposes, its value is inaccurate. Error studies include: position error, that is, the error of the position of the point, the error of the position of the line, and the error of the position of the polygon; the attribute error; the relationship between the position and the attribute error. Uncertainties in GIS include spatial location uncertainty, attribute uncertainty, time domain uncertainty, logical inconsistency, and data incompleteness. The uncertainty of the spatial position refers to the difference between the position of a described object in the GIS and the real object on the ground; attribute uncertainty refers to the difference between an attribute described by an object in the GIS and its real attribute; time domain uncertainty refers to an error in the description of time when describing a geographical phenomenon; logical inconsistency refers to inconsistencies within the data structure, especially inconsistencies in topological logic; the incompleteness of the data means that the GIS does not express the object as completely as possible for a given target. From the expression of spatial data to the generation of spatial data, from the processing of spatial data to the application of spatial data, there are data quality problems in both processes. In the following, according to the regularity of spatial data itself, the source of spatial data quality problems is expounded from several aspects. The spatial data quality problem first comes from the instability of the spatial phenomenon itself. The inherent instability of spatial phenomena includes spatial features and process uncertainties in space, thematic and temporal content. The spatial uncertainty of spatial phenomena refers to the uncertainty of its spatial position distribution; the temporal uncertainty of the spatial phenomenon is manifested by its migration over the time period of occurrence; the uncertainty of spatial phenomena in attributes is manifested by the diversity of attribute types and the inaccuracy of non-numerical attribute values.Therefore, the quality problem of spatial data is inevitable. The methods of measurement and the selection of measurement accuracy in data acquisition are influenced by human’s own understanding and expression, which will lead to errors in data generation. For example, in map projection, the projection conversion from ellipsoid to plane inevitably produces errors; all kinds of measuring instruments used to obtain various original data have certain design accuracy, such as the geographic position data provided by GPS have certain design accuracy required by users, so the generation of data errors is inevitable. In the process of spatial data processing, there are several errors that are easy to occur: Projection transformation: Map projection is a topological transformation from an open three-dimensional ellipsoid to a two-dimensional field plane. Under different projection forms, the location, area and direction of geographical features will be different. Map digitization and vector processing after scanning: errors may occur in the position accuracy, spatial resolution and attribute assignment of sampling points in the digitization process. Data format conversion: In the data format conversion between vector format and raster format, the position of the spatial features expressed by the data is different. Data Abstraction: Errors arising from operations such as clustering, aggregation, and merging during scale transformation of data, including knowledge-based inaccuracies and positional deviations in the spatial features represented by the data. Establishing topological relationship: The change of position coordinates accompanied by spatial features expressed by data in the process of topology. Matching with master data layer: In a database, multi-level data planes in the same area are often stored. In order to ensure the coordination of spatial positions among data layers, a master data layer is generally established to control the boundary and control points of other data layers. In the process of matching with the master data layer, there will also be spatial displacement, which will lead to errors. Data superposition operation and update: When data is superimposed and updated, there will be differences in spatial location and attribute values. Data integration processing: Refers to the errors in the process of interoperability of various data sets with different sources and types. Data integration is a complex process including data preprocessing, data interpolation and data expression, in which location error and attribute error will occur. Visual representation of data: In order to adapt to the visual effect in the process of data visualization, it is necessary to adjust the spatial feature location and annotation of data, which results in errors in data expression. The transmission and diffusion of errors in data processing: In each process of data processing, errors are accumulated and diffused, and the accumulated errors in the former process may become the origin of errors in the next stage, leading to the generation of new errors. Errors will also occur in the process of using spatial data, which mainly includes two aspects: one is the process of data interpretation, the other is the lack of documents. For the same kind of spatial data, different users may interpret and understand its content differently, the way to deal with this kind of problem is to provide various related documents with spatial data, such as metadata. In addition, the lack of descriptions of spatial data from different sources in a region, such as the lack of descriptive information such as projection type and data definition, often results in the random use of data by data users and the spread of errors. Table 5-1: Major sources of error in data Data processing Source of errors Data collection Field measurement errors: instrument errors, recording errors Remote sensing data error: radiation and geometric correction error, information extraction error Map data error: raw data error, coordinate conversion, cartographic synthesis and printing Data input Digital error: instrument error, operational error Format conversion errors of different systems: raster-vector conversion, triangulation-isoline conversion Data storage Insufficient numerical accuracy Spatial accuracy is not enough: Each grid point is too big, the minimum mapping unit is too big Data processing Unreasonable classification interval Error propagation caused by multi-layer data superposition: interpolation error, multi-source data comprehensive analysis error Errors caused by too small scale Data output Errors caused by imprecision of output equipment Errors caused by instability of output media Data usage Misunderstanding of the information contained in the data Improper use of data information The error in GIS refers to the difference between the data representation in GIS and its real world. The type of data error can be random or systematic.To sum up, there are four main types of data errors, namely geometric error, attribute error, time error and logic error. Among these errors, the attribute error and time error are consistent with the error concept in the general information system, the geometric error is unique to the geographic information system, and the geometric error, attribute error and time error will cause logic errors, so below mainly discuss logic errors and geometric errors. 1) Logic error The incompleteness of the data is reflected by the above four types of errors. In fact, checking for logic errors helps to find incomplete data and three other types of errors. Quality control or quality assurance or quality evaluation of data generally begins with a logical check of the data. As shown in Figure 5-4, the bridge or parking lot is connected to the road, if there is only a bridge or parking lot in the database, but it is not connected to the road, the road data is omitted and the data is incomplete. Fig. 65 Various logical errors # 2) Geometric error Because the map is expressed in two-dimensional plane coordinates, the geometric errors in two-dimensional plane are mainly reflected in points and lines. (2.1) Point error The point error about a point is the difference between the measured position (x, y) and its true position (x 0 , y 0 ). The measurement method of the real position is more accurate than the measurement position, as in the field using a high-precision GPS method. The point error can be obtained by calculating the coordinate error and distance. The coordinate error is defined as: Δx=x-x:sub:`0` Δy=y-y:sub:`0` In order to measure the point error in the entire data acquisition area or map area, the general sampling calculation (Δx, Δy). The sampling points should be randomly distributed in the data collection area and representative. Thus, the more sampling points, the closer the measured error distribution is to the true distribution of the point errors. (2.2) Linear error Lines can represent both linear phenomena and contiguous polygons in the GIS database. The first type is that points on the line can be found in the real world, such as roads, rivers, administrative boundaries, etc., the error of such linear features is mainly caused by measurement and post-processing of data; the second category is not found in the real world, such as the latitude and longitude lines defined by mathematical projections, contour lines drawn by elevation, or the climatic zone line and soil type boundaries, etc., the error in determining the bounds of a line is called the interpretation error. The interpretation error is directly related to the attribute error, if there is no attribute error, then the type boundary can be considered to be accurate, and the interpretation error is zero. In addition, the line is divided into lines, lines, and lines mixed with lines (Figure 5-5). Two methods are used to express curves and polylines in the GIS database. Figure 5-6 compares these two types of errors. Fig. 66 Various lines (straight lines, polylines, curves) # Fig. 67 Errors of polygons and curves # The Epsilon band is of equal width (similar to the buffer described later, but its meaning is different). On this basis, the error band model is proposed. Compared with the Epsilon band model, it is the narrowest in the middle and wider at the ends. Based on the error band model, the characteristics of the line and line error distribution can be regarded as the “bone type” or “chain type” error distribution band mode (Figure 5-7). Fig. 68 Distribution of polyline errors # For the error distribution of the curve, the “string-bowel model” should be considered (Fig. 5-8). Fig. 69 Error distribution of curves # Map data is data generated after an existing map has been digitized or scanned. In the map data quality problem, which not only contains the inherent errors of the map, but also includes errors such as drawing deformation and graphic digitization. Inherent map error: refers to the error of the map itself used for digitization, including control point error, projection error and so on. Since the relationship between these errors is difficult to determine, it is difficult to accurately evaluate the overall error. If it is assumed that there is a linear relationship between the combined error and various types of errors, the error propagation law can be used to calculate the integrated error. Error caused by material deformation: This type of error is due to the influence of humidity and temperature changes on the size of the drawing. If the temperature is constant, if the humidity is increased from 0% to 25%, the paper size may change by 1.6%; the expansion rate and shrinkage of the paper are not the same. Even if the humidity returns to its original size, the drawing cannot be restored to its original size, a 6-inch drawing may have an error of up to 0.576 inches due to humidity changes. During the printing process, the paper first becomes longer and wider as the temperature rises, and shrinks due to cooling. Image digitization error: The digitization method mainly includes tracking digitization and scanning digitization. Tracking digitization generally has two modes of operation, namely, a mode and a stream mode, the former is used more in actual work, and the latter is much more error-producing than the former. The impact of different data entry methods on data quality Tracking digitization: The main factors affecting the quality of its data are: digital feature objects, digital operators, digitizers, and digitization operations. Among them, the digital element object: the height, density and complexity of the geographic element graphic itself have a significant impact on the quality of the digitized result, for example, the thick line is more likely to cause errors than the thin line, the complex curve is more likely to cause errors than the flat line, and the dense elements are sparse, the elements are more likely to cause errors, etc.; Digital operators: the technology and experience of digital operators are different, and the digital errors introduced will also have large errors, which is mainly reflected in the selection of the best points, the ability to judge the degree of overlap between the crosshairs and the target, in addition, the degree of fatigue and digitization of digital operators can also affect the quality of digitization; the resolution and accuracy of the digitizer have a decisive influence on the quality of the digitization; the digital operation mode also affects the quality of the digitized data, such as the curve mining method (flow mode or point mode) and the density of the mining point. Scanning digitization: Scan digitization utilizes high-precision scanners to convert graphics and images into raster data files, which are then processed by scanning vectorization software to transform them into vector graphic data. The vectorization process can be implemented in two modes: interactive and fully automatic. Factors influencing the quality of scanned digital data include the original map quality (such as clarity), scanning accuracy, scanning resolution, registration precision, and correction accuracy. The quality of remote sensing data comes from the observation process of remote sensing instruments and partly from the process of remote sensing image processing and interpretation. The remote sensing observation process itself has limitations on accuracy and accuracy, the errors generated by this process are mainly spatial resolution, geometric distortion and radiation error, which will affect the position and attribute precision of remote sensing data. The remote sensing image processing and interpretation process mainly produces errors in spatial position and properties. This is introduced by image or image correction and matching in image processing and interpretation and classification of remote sensing interpretation, including attribute errors caused by interpretation interpretation of mixed pixels. The measurement data mainly refers to the spatial position information of the measurement object obtained by direct measurement using geodetic survey, GPS, urban measurement, photogrammetry and some other measurement methods. This part of the data quality problem is mainly the positional error of spatial data. The position of the spatial data is usually represented by coordinates, there is a certain error factor between the coordinates of the spatial data position and its latitude and longitude, since this error factor cannot be excluded, it is generally not considered as an error. Measurement errors typically account for system errors, operational errors, and accidental errors. The occurrence of systematic errors is related to a certain system, which is caused by a combination of environmental factors (such as temperature, humidity and pressure), instrument structure and performance, and operator skills. Systematic errors cannot be checked or eliminated by repeated observations and can only be simulated and estimated using digital models. Operational errors are caused by carelessness or mishandling by the operator when using the device, reading a book, or recording observations. Various methods should be used to check and eliminate operational errors. In general, operational errors can be verified for consistency by simple geometric relationships or algebraic checks, or by repeated observations to check for operational errors. Accidental error is a random error introduced by some unmeasurable and uncontrollable factors. This kind of error has certain characteristics, such as the same frequency of positive and negative errors, less large errors, and more small errors. Accidental errors can be estimated and processed using a stochastic model. Data quality control is a complex process, to control data quality, we should start with all the processes and links of data quality generation and diffusion, and reduce the error by certain methods. Common methods for spatial data quality control are: The manual method of quality control mainly compares the digitized data with the data source, the inspection of the graphic part includes the visual method, the comparison to the transparent image and the original image overlay, and the inspection of the attribute part is compared with the original attribute one by one or other comparison methods. The metadata of the dataset contains a large amount of information about the quality of the data, through which the quality of the data can be checked, and the metadata also records the quality changes in the data processing process. The status and changes of the data quality can be understood with tracking the metadata. The quality of the data is analyzed using the correlation of the geographical feature elements of the spatial data itself. If the spatial distribution of the natural features of the surface is analyzed, the mountain river should be at the lowest point of the micro-topography, therefore, when superimposing the two layers of data of the river and the contour, if the position of the river is not on the convex line of the contour, then Explain that there must be a quality problem in the two layers of data, if you can’t determine which layer of data has a problem, you can further analyze it by superimposing them with other reliable data layers. Therefore, a knowledge base on the relationship of geographic feature elements can be established for the correlation analysis of geographic feature elements between spatial data layers.Basic concepts of data quality #
Accuracy #
Precision #
Spatial resolution #
Scale #
Error #
Uncertainty #
Source of spatial data quality issues #
Instability of spatial phenomena itself #
Expressions of spatial phenomena #
Error in spatial data processing #
Errors in the use of spatial data #
Error analysis of common spatial data #
Types of errors #
Quality problems of map data #
Quality problems of remote sensing data #
Quality problems of measurement data #
Spatial data quality control #
Traditional manual method #
Metadata method #
Geographic correlation method #