Six steps teach you to use python crawler to crawl data
Python crawls out of the six steps
Step 1:Install the requests library and the Beautiful Soup library
In the program, the two libraries are written as follows:
import requests
from bs4 import BeautifulSoup
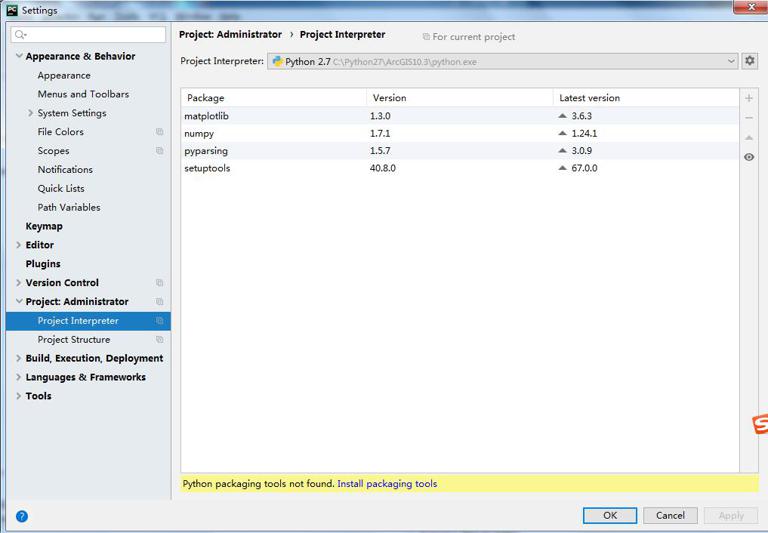
Because I use python programming by pycharm. So I will talk about how to install these two libraries on pychar. Under the main page file option, find the settings. Find the project interpreter further. Then in the selected box, click the+sign on the software package to query the plug-in installation. Hxd with compiler plug-in installation is expected to be better to start with.
Step 2: Get the headers and cookies required by the crawler
I wrote a crawler program to crawl Weibo hot search. Let's take it as an example. Getting headers and cookies is necessary for a crawler. It directly determines whether the crawler can accurately find the location of the web page for crawling.
First, enter the hot search page of Weibo, press F12, and the js language design part of the page will appear. As shown in the figure below. Find the Network section on the web page. Then press ctrl+R to refresh the page. If there is file information during the process, there is no need to refresh. Of course, there is no problem with refreshing. Then, we browse the Name section, find the file we want to crawl, right click, select copy, and copy the URL of the page.

After copying the URL, we will enter a web page Convert curl commands to code. This page can automatically generate headers and cookies according to the URL you copied, as shown below. The generated headers and cookies can be directly copied and pasted into the program.
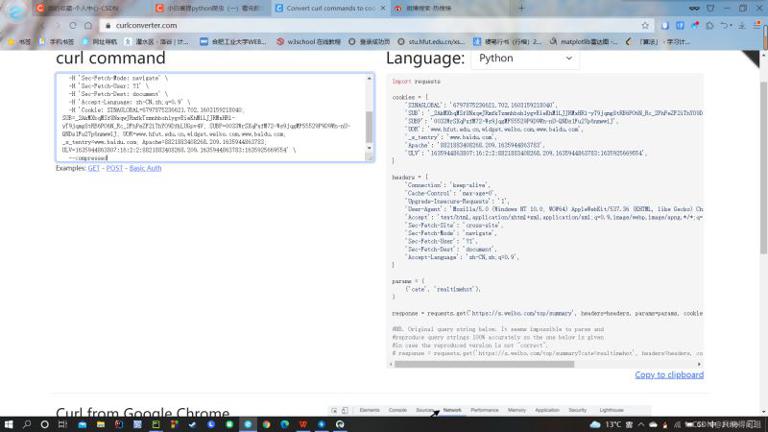
#Crawler header data
cookies = {
'SINAGLOBAL': '6797875236621.702.1603159218040',
'SUB': '_2AkMXbqMSf8NxqwJRmfkTzmnhboh1ygvEieKhMlLJJRMxHRl-yT9jqmg8tRB6PO6N_Rc_2FhPeZF2iThYO9DfkLUGpv4V',
'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9Wh-nU-QNDs1Fu27p6nmwwiJ',
'_s_tentry': 'www.baidu.com',
'UOR': 'www.hfut.edu.cn,widget.weibo.com,www.baidu.com',
'Apache': '7782025452543.054.1635925669528',
'ULV': '1635925669554:15:1:1:7782025452543.054.1635925669528:1627316870256',
}
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/25',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'cross-site',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
params = (
('cate', 'realtimehot'),
)
Copy it into the program like this. This is the request header of Weibo hot search.
Step 3: Get the web page
After we get the header and cookie, we can copy it into our program. Then, use the request request to get the web page.
#Get web page
response = requests.get('https://s.weibo.com/top/summary', headers=headers, params=params, cookies=cookies)
Step 4: Parse the webpage
At this time, we need to go back to the web page. Also press F12 to find the Elements section of the web page. Use the small box with an arrow in the upper left corner, as shown in the following figure. Click the content of the page, and the page will automatically display the corresponding code of the page you obtained on the right.
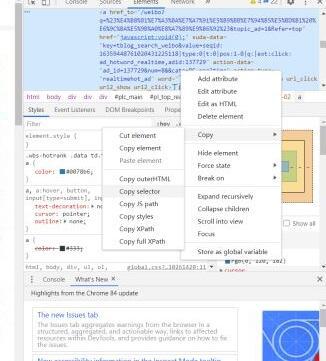
As shown in the figure above, after we find the page code of the page we want to crawl, we place the mouse on the code, right click, and copy to the selector section. As shown above.
Step 5: Analyze the obtained information and simplify the address
In fact, the selector just copied is equivalent to the address stored in the corresponding part of the page. Because we need a kind of information on the web page, we need to analyze and extract the obtained address. Of course, you can only get the content of the page you choose.
#pl_top_realtimehot > table > tbody > tr:nth-child(1) > td.td-02 > a
#pl_top_realtimehot > table > tbody > tr:nth-child(2) > td.td-02 > a
#pl_top_realtimehot > table > tbody > tr:nth-child(9) > td.td-02 > a
These are the three addresses I obtained. We can find that the three addresses have many similarities. The only difference is the tr part. Since tr is a web page tag, the following part is its supplementary part, that is, the subclass selector. It can be inferred that this kind of information is stored in the subclass of tr. We can directly extract the information from tr to obtain all the information corresponding to this part. So the refined address is:
#pl_top_realtimehot > table > tbody > tr > td.td-02 > a
Hxd, which has a certain understanding of js-like languages in this process, is expected to be better handled. However, it doesn't matter if there is no js-like language foundation. The main step is to keep the same part. Try it slowly and it will always be right.
Step 6: Crawl content and clean data
After this step is completed, we can directly crawl the data. Use a tag to store the extracted things like addresses. The tag will pull the page content we want to get.
#Crawling content
content="#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"
After that, we need to filter out unnecessary information, such as js language, and eliminate the interference of such language on the reading of information audiences. In this way, we can successfully crawl down the information.
fo = open("./Weibo's trendy.txt",'a',encoding="utf-8")
a=soup.select(content)
for i in range(0,len(a)):
a[i] = a[i].text
fo.write(a[i]+'\n')
fo.close()
I store the data in the folder, so there will be write operations brought by wirte. Where you want to save the data or how you want to use it depends on the reader.
Code examples and results of crawling Weibo's trendy
import os
import requests
from bs4 import BeautifulSoup
#Crawler header data
cookies = {
'SINAGLOBAL': '6797875236621.702.1603159218040',
'SUB': '_2AkMXbqMSf8NxqwJRmfkTzmnhboh1ygvEieKhMlLJJRMxHRl-yT9jqmg8tRB6PO6N_Rc_2FhPeZF2iThYO9DfkLUGpv4V',
'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9Wh-nU-QNDs1Fu27p6nmwwiJ',
'_s_tentry': 'www.baidu.com',
'UOR': 'www.hfut.edu.cn,widget.weibo.com,www.baidu.com',
'Apache': '7782025452543.054.1635925669528',
'ULV': '1635925669554:15:1:1:7782025452543.054.1635925669528:1627316870256',
}
headers = {
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.6241 SLBChan/25',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'cross-site',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
params = (
('cate', 'realtimehot'),
)
#Data storage
fo = open("./Weibo's trendy.txt",'a',encoding="utf-8")
#Get web page
response = requests.get('https://s.weibo.com/top/summary', headers=headers, params=params, cookies=cookies)
#Parse web pages
response.encoding='utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
#Crawling content
content="#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"
#Cleaning data
a=soup.select(content)
for i in range(0,len(a)):
a[i] = a[i].text
fo.write(a[i]+'\n')
fo.close()