Advantages and disadvantages of the four methods of Python crawler
How to use crawlers to achieve the following requirements? The pages to be crawled are as follows (URL: https://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0 ):
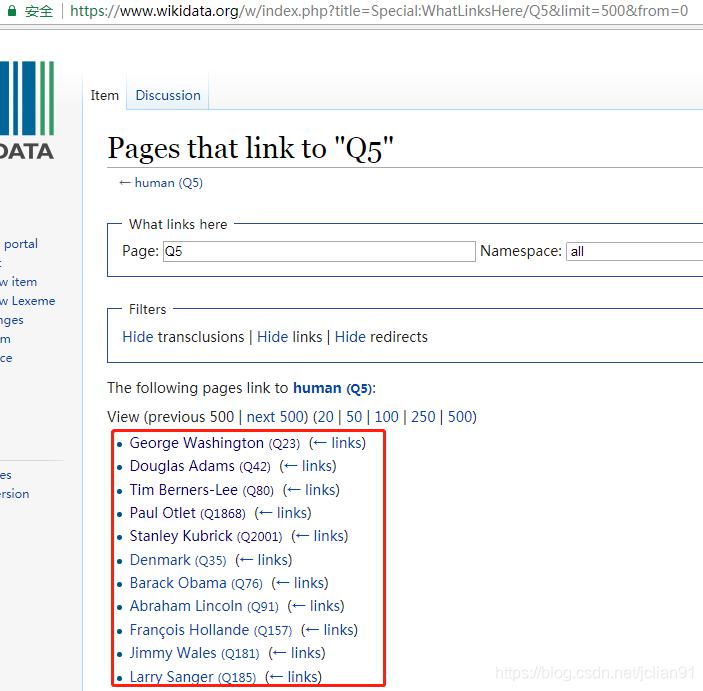
Our need is to crawl the name of the celebrity in the red box (there are 500 records, and the picture only shows part of it) and its introduction. For its introduction, click the name of the celebrity, as shown in the following figure:
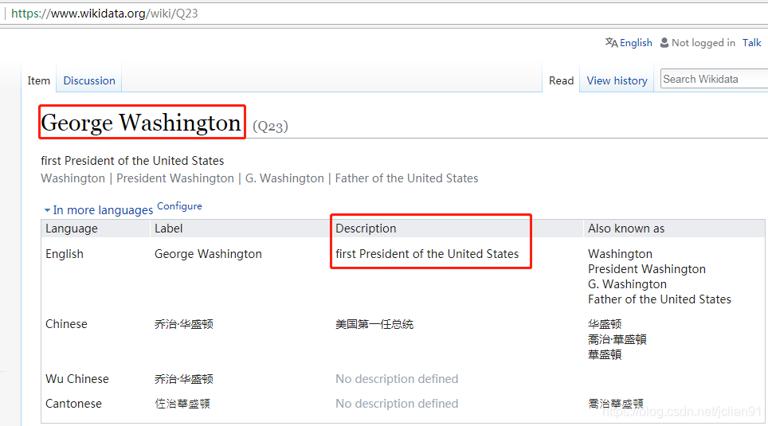
This means that we need to crawl 500 such pages, that is, 500 HTTP requests (let's put it this way), and then extract the names and descriptions in these pages. Of course, some are not celebrities, and there are no descriptions. We can skip. Finally, the web addresses of these pages can be found after the celebrities on the first page, for example, George Washington's web page suffix is Q23. This is probably what reptiles need.
Positions of reptiles
First of all, analyze the idea of crawling: first, on the first page( https://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0 ). Get the websites of 500 celebrities, and then crawl the names and descriptions of celebrities in the 500 pages. If there is no description, skip.
Next, we will introduce four methods to implement this crawler, and analyze their advantages and disadvantages, hoping to give readers more experience of the crawler. The method to implement the crawler is:
- General method (synchronization, requests+Beautiful Soup)
- Concurrency (using the concurrent. futures module and requests+Beautiful Soup)
- Asynchronous (use aiohttp+asyncio+requests+Beautiful Soup)
- Use Frame Scrap
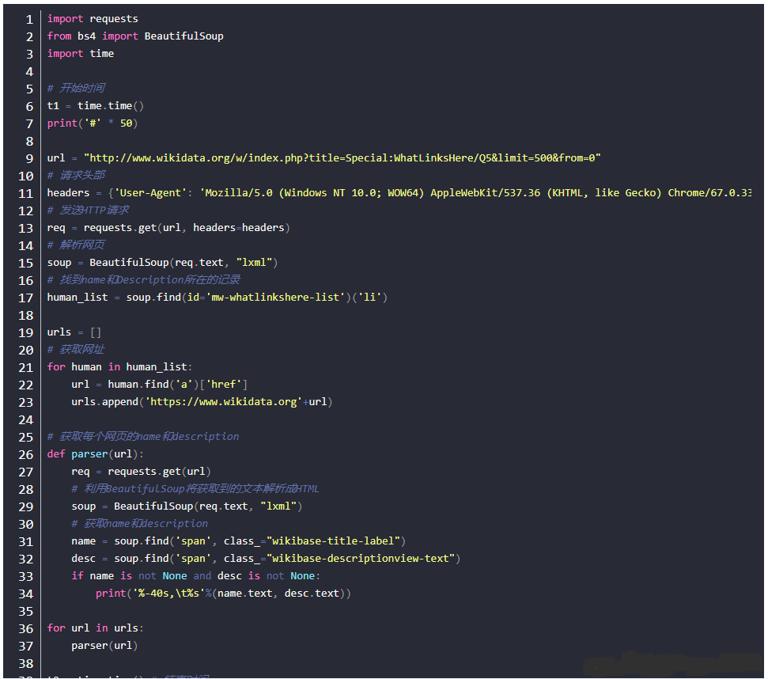
General method
The general method is the synchronization method, which mainly uses requests+Beautiful Soup and executes in sequence. The complete Python code is as follows:
The output results are as follows (omit the middle output and replace it with...):

The synchronization method takes about 725 seconds, or more than 12 minutes. Although the general method is simple and easy to implement, it is inefficient and time-consuming. Then, try concurrency.
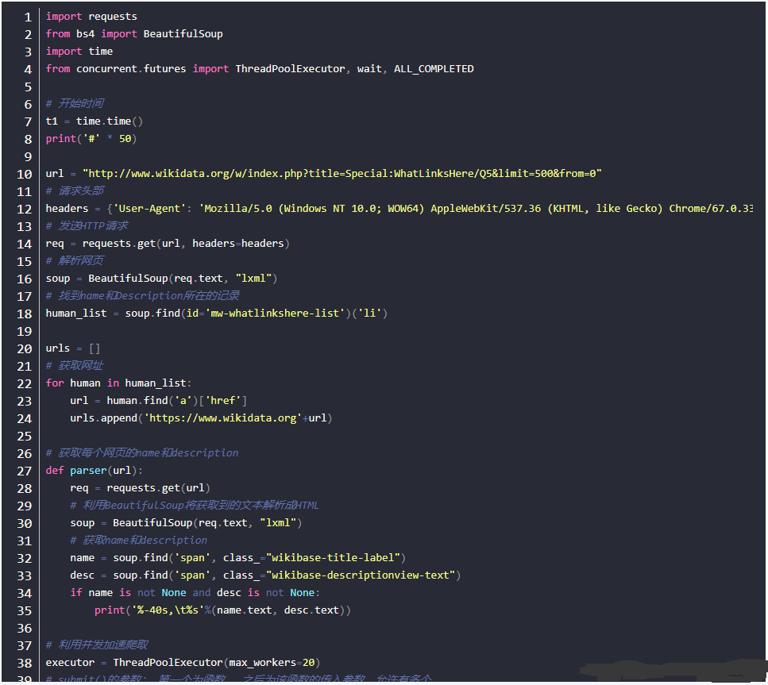
Concurrent method
The concurrency method uses multithreading to speed up the general method. The concurrency module we use is the concurrent.futures module. The number of multithreads is set to 20 (which may not be achieved in practice, depending on the computer). The complete Python code is as follows:
The output results are as follows (omit the middle output and replace it with...):
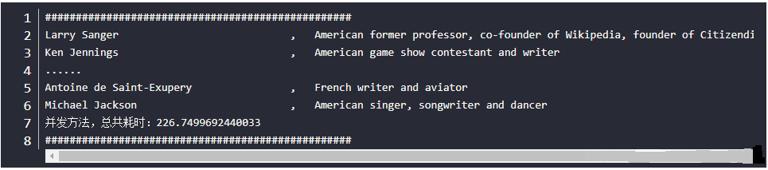
The execution time of the crawler after using multithreading concurrency is about 227 seconds, which is about one third of the time of the general method. The speed has been significantly improved! The speed of multithreading is significantly improved, but the order of the executed pages is disordered, and the cost of thread switching is also relatively high. The more threads, the higher the cost.
Asynchronous method
Asynchronous method is an effective way to improve speed in crawlers. Using aiohttp can process HTTP requests asynchronously, and using asyncio can achieve asynchronous IO. It should be noted that aiohttp only supports Python versions after 3.5.3. The complete Python code for implementing the crawler using the asynchronous method is as follows:
The output results are as follows (omit the middle output and replace it with...):
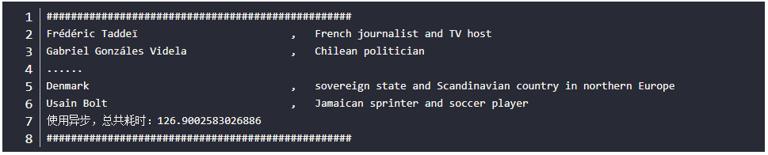
Obviously, the asynchronous method uses two speed-up methods, asynchronous and concurrent, and the speed is obviously improved, about one sixth of that of the general method. Although the asynchronous method is efficient, it needs to master asynchronous programming, which requires learning for a period of time.
If someone thinks that the 127-second crawling speed is still slow, they can try asynchronous code (the difference from the previous asynchronous code is that they only use regular expressions instead of BeautifulSoup to parse the page to extract the content in the page):
The output results are as follows (omit the middle output and replace it with...):
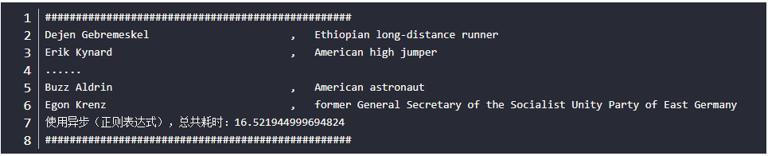
16.5 seconds, which is only one 43rd of the general method, is so fast and amazing (thanks for someone's attempt). Although the author has implemented the asynchronous method himself, he uses BeautifulSoup to parse the web page, which takes 127 seconds. He did not expect that the use of regular expressions has achieved such amazing results. It can be seen that Beautiful Soup is fast in parsing web pages, but in the asynchronous method, it still limits the speed. However, the disadvantage of this method is that when the content you need to crawl is complex, the general regular expression is not competent, and you need to find another way.
Crawler frame
Finally, we use the famous Python crawler framework, Scrap to solve this problem. The crawler project we created is wikiDataScrap. The project structure is as follows:
Set "ROBOTSTXT_OBEY=False" in settings. py Modify items.py with the following code:

Then, create a new wikiSpider.py under the spiders folder. The code is as follows:
The output results are as follows (only the summary of the last Scrap information is included):
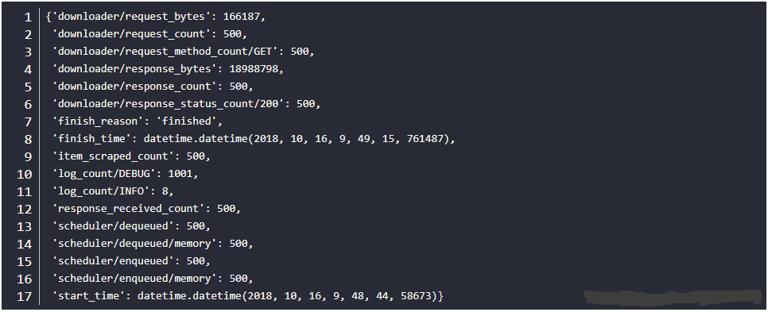
You can see that 500 pages have been successfully crawled, taking 31 seconds, and the speed is also quite good. Let's take a look at the generated wiki.csv file, which contains all the output names and descriptions, as shown in the following figure:
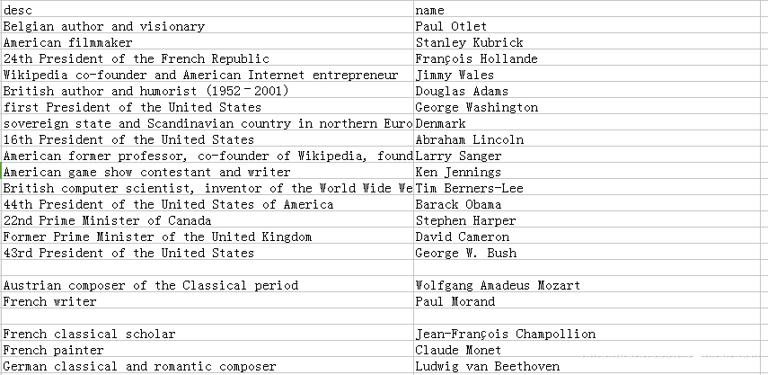
You can see that the columns of the output CSV file are not orderly. As for how to solve the problem of newline in the CSV file output by the Scrap, please refer to the answer on the stackhoverflow: https://stackoverflow.com/questions/39477662/scrapy-csv-file-has-uniform-empty-rows/43394566#43394566 。
The advantage of using Scrapy to create a crawler is that it is a mature crawler framework that supports asynchronous, concurrent, and good fault-tolerance (for example, this code does not deal with cases where the name and description cannot be found). However, if you need to modify the middleware frequently, it is better to write a crawler yourself, and it is not faster than the asynchronous crawler we write ourselves. As for the function of automatically exporting CSV files, it's quite real.
Summary
This article has a lot of content. It compares four crawler methods. Each method has its own advantages and disadvantages, which have been given in the previous statement. Of course, in practical problems, the more advanced the tools or methods used, the better.