The composition of an information system and its database depends on the application purpose, data type and working mode of the system. The content and function of GIS, as well as an important characteristic of GIS, or the difference between GIS and general management information system, are the spatial distribution of data. As far as GIS is concerned, not only the data itself has spatial attributes, but also the analysis and application of the system are directly related to the geographical environment. This basic characteristic of the system profoundly affects the data structure, database design, analysis algorithm and software, as well as the input and output of the system. From the point of view of data sources, graphics and image data are the main sources of GIS data, and the results of analysis and processing are often expressed in graphics. The general management information system is mainly based on statistical data and tabular data. This also makes the geographic information system different from the general management information system in hardware and software. In hardware, in order to process graphics and image data, the system needs to configure special input and output equipment, such as digitizer, plotter, graphics and image display equipment, etc. Many field acquisition and observation of stations get resource information in the form of analog quantity, and the system also needs to configure analog-digital conversion equipment, which often exceeds the price of Central Processing Unit, and the volume is also large. In software, it is required to develop special analysis algorithms and processing software for graphics and image data. These algorithms and software are directly related to data structure and database management methods. In terms of content and purpose of information processing, general management information systems, mainly inquiry and retrieval, statistical analysis and processing results, are mostly tabular data in a specified format. Geographic Information Systems, in addition to basic information retrieval and statistical analysis, are mainly used to analyze the rational development and utilization of resources, formulate regional development plans and regions. The comprehensive control scheme, which monitors and predicts the environment dynamically, provides scientific basis for decision-making in national economic construction, and provides information and guidance for production practice. Because GIS is a complex natural and social integration, the processing of information must be a comprehensive analysis of multiple factors. Systematic analysis is a basic method to study the relationship among the components of a certain geographic information system, to establish the mathematical model of the system by using statistical data, to make mathematical planning according to the given objective function, and to seek the optimal scheme so as to optimize the economic benefits of the system. Or the method is to analyze the feedback links between the various parts of the system and to establish the structural model of the system. By using the method of system dynamics, it carrys out the dynamic analysis, and studys the change of system state and the prediction of development trend. Computer simulation is an effective and economical analysis method, which is easy to analyze the influence of various factors and compare schemes. It is often used in many applications of natural environment and social economy. In addition, GIS also has the functions of analysis and measurement, such as calculating area, length, density, distribution characteristics and the relationship between geographical entities. Geographic information system and general information management system have many similarities. Both of them are computer-based information processing systems, which have the characteristics of large amount of data and complex relationship between data. They are also constantly improving and perfecting with the development of database technology. Comparatively, the commercial management information system develops rapidly, the number of users is large, and the existing stereotyped software products can be selected, which also promotes the standardization of software systems. Geographic information system, because of the above characteristics, is designed specially according to the specific application requirements. The data format and organizational management methods are different. At present, there are hundreds of spatial data processing systems and software packages abroad, and almost no two systems are the same. Although standardization is considered very important and many efforts have been made (for example, establishing standards and norms for computer graphics), the algorithms and software systems for analysis are still not standardized. In fact, GIS is becoming a separate research and development field as a processing system of spatial information. Database serves a certain purpose and stores related data sets with specific data. It is the advanced stage of data management and is developed from the file management system. The database of geographic information system (referred to as spatial database or geographic database) is a data set about the characteristics of certain geographic elements in a region. In order to understand the database intuitively, the database can be compared as follows: Table 7-1: Comparisons between databases and libraries Database Libraries Data Books Data model Book cataloging Physical organization of data Books Storage Rules, Bookshelves Database Management System Librarian External memory Stack room User Readers Data access Book reading Compared with general databases, spatial databases have the following characteristics: The data volume is particularly large. A geographic system is a complex integrated entity, and data is required to describe various geographic elements, especially the spatial locations of these elements, which often results in a substantial data volume. There are not only attribute data of geographical elements (similar to the data in general databases), but also a large number of spatial data, that is, data describing the spatial distribution of geographical elements, and there is an inseparable relationship between the two data. Data are widely used, such as geographic research, environmental protection, land use and planning, resource development, ecological environment, municipal administration, road construction, etc. Database is a combination of information about things and their relationships. Early database objects and their attributes are stored separately, which can only satisfy simple data recovery and use. Data definitions are defined by specific data structures and stored in file format, which is called file processing system. File processing system is the most common method of database management, but there are many shortcomings. First, every application must directly access the data files used. The application program relies entirely on the storage structure of the data files, and the application program will be modified when the data files are modified. The other problem is the sharing of data files. Since several users or applications share a data file, modification of the data file must be approved by all users. Lack of centralized control also brings a series of database security problems. The integrity of the database is strict and the quality of information is worse than that without information. Database Management System (DBMS) is a system developed on the basis of file processing system. DBMS serves as a bridge between user applications and data files. The greatest advantage of DBMS is that it provides data independence between the two, that is, when an application accesses a data file, it does not need to know the physical storage structure of the data file. When the storage structure of data files changes, there is no need to change the application. Major problems of using standard DBMS to store spatial data Using standard DBMS to store spatial data is not as good as storing tabular data. The main problems include: In GIS, spatial data records become longer, because the number of stored coordinate points is varies, while general databases only allow the length of records to be set to a fixed length. Moreover, DBMS has serious shortcomings in storing and maintaining spatial data topology. Therefore, additional software functions are generally added to standard DBMS. Generally, DBMS is difficult to implement basic operations such as association, connection, inclusion and superposition of spatial data. GIS needs some complex graphics functions, which can not be supported by general DBMS. Geographic information is highly complex. Representing a single geographic entity often requires multiple files and records, which may include geodetic networks, feature coordinates, topological relationships, spatial feature measurements, keywords for attribute data, and non-spatial thematic attributes. Conventional DBMS often struggle to handle such complexity. GIS data records with highly interconnected relationships require a more sophisticated security maintenance system. To ensure the integrity of the spatial database and protect the completeness of data files, protection mechanisms must be stored together with the spatial data. Otherwise, modifying a single record may cause errors in other data files. Conventional DBMS are generally unable to guarantee these requirements. Four main types of GIS data management methods Developing independent data management services for different application models is a method based on file management. Develop additional systems on the basis of commercial DBMS. Develop an additional software to store and manage spatial data and spatial analysis, and use DBMS to manage attribute data. It is based on DBMS and the functions of the system need to expand using by existing DBMS. Spatial data and attribute data are managed by the same DBMS. A sufficient number of software and functions need to be added to provide spatial functions and graphical display functions. Redesign a database system with spatial data and attribute data management and analysis functions. Data is the carrier of information in the real world and the concrete expression form of information. In order to express meaningful information content, data must be organized and stored in a certain way. Data organization in databases can generally be divided into four levels: data items, records, files and databases. 1) Data items Data item is the smallest unit of defined data, also called elements, basic items, fields, etc. Data item corresponds to the attributes of real-world entities. Data item has a certain range of values, which is called domain. Any value outside the domain is meaningless to the data item. Each data item has a name called a data item. The values of data items can be numeric, alphanumeric, alphanumeric, and Chinese characters. The physical characteristic of data item is that it has definite physical length and can be viewed as a whole. 2)Records Record is composed of several related data items. It is the basic unit of processing and storing information. It is the sum of data entity. The data items that constitute the record represent several attributes of the entity. Records differ between “value” and “type”, the “type” is the framework of similar records, which defines records, and “value” is the content of records reflecting entities. In order to uniquely identify each record, there must be a record identifier, also known as a keyword. Record identifier is generally the first data item in the record. The key that uniquely identifies the record is the primary key, and the other key that identifies the record is the auxiliary key. Records can be divided into logical records and physical records. Logical records are data units in a file that are divided according to the logical independent meaning of information. Physical records are the basic unit for data access by a single input and output command. The corresponding relationship between physical records and logical records has a physical record corresponding to a logical record. A physical record contains several logical records and several physical records store a logical record. 3)Files A file is a collection of all specific values of a given type of (logical) record. The file is identified by the name of the file. According to the organization and access method of the record, the file can be divided into sequential file, index file, direct file and inverted file. 4) Database A database is a larger data organization than a file. A database is a collection of data with a specific connection. It can also be regarded as a collection of records of various types with a specific connection. The internal structure of the database is a files collection , which make some connection and cannot exist in isolation. The logical relationship between data mainly refers to the connection among records. Records represent entities in the real world. There are one or more links between entities, and such links must be reflected in the links between records. There are three main logical links between data: one-to-one links, one-to-many links and many-to-many links. Fig. 87 Non-sequential files # File organization is a part of data organization. Data organization not only refers to the organization of data in memory, but also refers to the organization of data in memory. Document organization mainly refers to the organization of data recorded on memory devices. It is managed by OS, specifically, how to arrange data and organize data on memory devices, and how to access data. The file organization method implemented by operating system can be divided into sequential file, index file, direct file and inverted file. 1) Sequential files Sequential files are the simplest form of file organization, organizing records in the order of primary keywords (Figure 7-2). When the primary keyword is numeric, it is in order of its numerical value. If the primary keyword is literal, it is in alphabetical order. All records on magnetic tape can only be sequential, while records on disk can be either sequential or random. Records of sequential files are logically sorted by primary keywords, but there are different ways of physical storage, including vector mode, chain mode and block chain. The vector mode is the stored files that are stored continuously by address, the physical structure is consistent with the logical structure. The chain mode is the files that are not stored continuously by address, the logical order of files is realized by chain, and each record in the file contains a pointer. To specify the storage address of the next record. The block chain divides file into several data blocks, which are connected by pointers, while the blocks are stored continuously. Fig. 88 Sequential files # 2) Index files In addition to storing the record itself (main file), index files also establish several index tables, which are called index files. The index table lists the record keywords and the location (address) of the record in the file. When reading records, as long as the keyword value of the records is provided, the system obtains the location of the records by looking up the index table, and then extracts the records. Index tables are generally sorted. They can be either sequential or non-sequential, single-level or multi-level. Multi-level index can improve the search speed, but it takes up a large amount of storage space. 3) Direct documents Direct file is also called random file. Its storage is to get a physical storage location by some conversion method according to the value of the record keyword, and then store the record in that location. The required records can be obtained directly by the same transformation method when it is researching. 4) Inverted documents Inverted files are files with auxiliary indexes, in which auxiliary indexes are organized according to some auxiliary keywords (note: index files are indexed according to the primary keywords of records, also known as the main index). Inverted file is a multi-keyword index file, in which the index can not uniquely identify records, often the same index points to several records. Thus, an index often has a pointer table pointing to all the records identified by the index. Records cannot be read directly through auxiliary indexes, but the location of records can be found only through primary keywords. The main advantage of inverted files is that when dealing with multi-index retrieval, the logical operations of query such as “intersection” and “union” can be completed first in auxiliary retrieval, and then the records can be accessed after the results are obtained, so as to improve the search speed. The organization method of describing the data itself of geographical entities is called internal data structure. Spatial data structure refers to the logical structure of geographic graphics suitable for storage, management and processing of computer systems. It is an abstract description of spatial arrangement and relationship of geographic entities. It is a kind of understanding and interpretation of data. It does not show that the data of data structure is useless. Not only the user can not understand, but also the computer program can not process correctly. Processing the same set of data according to different data structures may result in different contents. Spatial data structure is the bridge of communication information in GIS. Only by fully understanding the specific data structure adopted by GIS, can the system be used correctly. Internal data structure can be basically divided into two categories: the vector structure and raster structure (also known as vector model and raster model) (Figure 7-3). Both types of structures can be used to describe three basic types of geographical entities: point, line and surface. Spatial data coding is the realization of spatial data structure. It is the process of converting data collected according to the purpose and task of GIS, such as audited topographic maps, thematic maps and remote sensing images into data suitable for computer storage and processing according to specific data structure. Because of the huge amount of data in GIS, the encoding method of compressed data is usually used to reduce data redundancy. In the spatial data structure of GIS, the encoding methods of raster structure mainly include direct raster coding, chain coding, run length coding, block coding, quadtree coding, and vector structure mainly includes coordinate sequence coding, tree index coding and binary topology coding. Fig. 89 Vector structure and raster structure # In the vector model, the location and scope of the real world elements can be expressed by points, lines or planes, similar to their representation on maps. The location of each entity is defined by their spatial position (coordinates) in the coordinate reference system. Each location in the map space has a unique coordinate value. Points, lines and polygons are used to express the state of irregular geographical entities in the real world (polygons are boundaries of enclosed areas surrounded by several straight lines). A line may express a road, a polygon may express a woodland, etc. The spatial entity in the vector model corresponds to the spatial entity in the real world. In a grid model, space is regularly divided into grids (the shape is usually square). The location and status of geographic entities are defined by the rows and columns of the grid they occupy. The size of each grid represents the defined spatial resolution. Since the location is defined by the grid row number, the specific location is determined by the nearest grid record. For example, an area is divided into 10*10 grids, so only those 10*10 location of objects are recorded near 10 gridsare. The value of the grid represents the type or state of the object in this position. Using the grid method, the space is divided into a large number of regular grids, and the values of each grid may be different. A spatial element is a grid, and each grid corresponds to a specific spatial location, such as an area of the surface. The value of the grid represents the state of the location. Unlike the vector model, the smallest element of the grid model has no direct correspondence with the real world spatial entities. Spatial entity units in raster data model are not conceptually understood objects, they are only separate grids. For example, the road does not exist as a clear grid, and the value of the grid expresses that the road is an entity. The road is expressed by a group of grids with road attribute values, which can not be identified by a grid entity. In both data structures, spatial information is expressed in a unified unit. In the grid method, the unified unit is the grid (the grid is not separable, its attributes are used to express the properties of the object at the corresponding position), and the number of grids used to express an area is large, but the size of the grid unit is the same. The raster data file contains millions of rasters, and the location of each raster is strictly defined. In the vector method, the unified units are points, lines and polygons. Compared with the grid method, the number of units used is less, but the size is variable. In vector files, the number of elements may be thousands, but after all, there is not as much raster data. The position of the same type of vector element is defined by the continuous coordinate value. The coordinate position provided by vector data is more accurate than that expressed by row and column numbers in raster data. These two methods have their own advantages and disadvantages. What kind of data structure depends on the purpose of using data. Some geographic phenomena are more suitable to be expressed by raster data. Some geographic phenomena are more advantageous to be expressed by vector data in order to express the spatial relationship between them. Principles, Technologies, and Methods of Geographic Information Systems 102 In recent years, Geographic Information Systems (GIS) have undergone rapid development in both theoretical and practical dimensions. GIS has been widely applied for modeling and decision-making support across various fields such as urban management, regional planning, and environmental remediation, establishing geographic information as a vital component of the information era. The introduction of the “Digital Earth” concept has further accelerated the advancement of GIS, which serves as its technical foundation. Concurrently, scholars have been dedicated to theoretical research in areas like spatial cognition, spatial data uncertainty, and the formalization of spatial relationships. This reflects the dual nature of GIS as both an applied technology and an academic discipline, with the two aspects forming a mutually reinforcing cycle of progress.Comparison between geographic information system and general management information system #
The difference between the two #
The similarities between them #
Spatial database #
Concept of Database #
Characteristics of Spatial Database #
Database Management System #
Data and File Organization #
Classification of data organization #
Logical links between data #
Common data files #

Internal Data Structure of GIS-Vector Structure and Raster Structure #
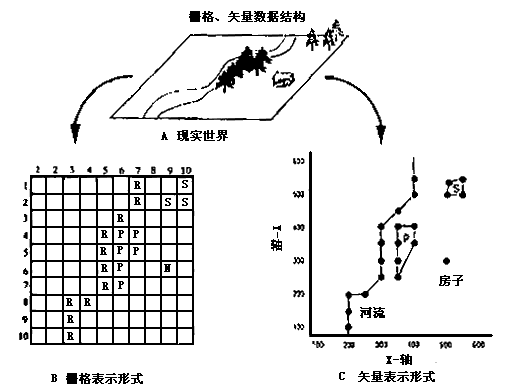
Vector model #
Raster model #