Data management design
The purpose of the data management part is to determine the basic structure of storing and retrieving data in the data management system, and its principle is to isolate the influence of the data management scheme. whether the scheme is a common file, relational database, object-oriented database or other way.
At present, there are three main methods of data management, namely, file, relational and object-oriented.
General document management: general document management provides basic document processing and classification capabilities
Relational database management system (RDBMS): based on relational theory, relational database management system uses multiple tables to manage data, and the structure of each table is standardized according to a series of “paradigms” in order to reduce data redundancy.
Object-oriented database management system: object-oriented database is a mature technology, which realizes the continuous storage of objects by adding abstract data types and inheritance features as well as some used to create and manipulate classes and object services.
No matter what method is used in the analysis phase, whether it has been implemented with OOPL or non-OOP, you can choose any of the above schemes to achieve data management.
In the GIS software, the data to be managed mainly include: spatial geometry data, time data, structured non-spatial attribute data and unstructured description data. For example, for parcels in a cadastral management system
Spatial geometry data: coordinates of parcel boundary point
Time data: the period of time during which the parcel exists
Non-spatial attribute data: ownership of parcels, land price, etc.
Unstructured description data: image, sound data, etc., needed to describe parcels.
In order to manage this data, common scenarios include:
All adopt file management
Store all data in one or more files, including structured attribute data. The advantage of using file management data is flexible, that is, each software manufacturer can define its own file format and manage all kinds of data at will. This is helpful when storing data that need to be encrypted and unstructured, variable-length geometry coordinate records. The disadvantage of file management is also obvious, that is, developers need to update, query and retrieve attribute data, which can be done by relational database, in other words, the use of file management increases the amount of development of attribute data management, and is not conducive to data sharing. At present, many GIS software use text format files for data storage, the purpose is to achieve data transfer and transfer, and exchange data with other application systems.
File combined with relational database management
This is the data management scheme adopted by most GIS software at present. Considering that spatial data is unstructured and variable in length, and the operation imposed on spatial data needs to be realized by GIS software, we can use files to store spatial data and manage attribute data with the help of the existing relational database management system (RDBMS). In this way of management:
Spatial data: managing through fil
Time data: it is structured and can be managed by database
Non-spatial attribute data: managing with database
Unstructured description data: because the description data, whether text, image, sound or video, generally corresponds to a file, the file path can be simply recorded in the relational database. Its advantage is that the amount of data in the relational database is small, but the disadvantage is that the file path often becomes unreliable because of file deletion and moving operations. If the relational database supports binary block fields, you can also use it to manage text, images, and even sound and video files.
Because spatial geometry coordinate data and attribute data are stored and managed separately, it is necessary to define the corresponding relationship between them. The usual solution is that in the file, each figure has a unique identification code (figure ID), and in the relational data table structure, there is also an identification code attribute, so that each record can determine the connection with the corresponding figure through this identification code (figure 16-11).
The disadvantage of this management mode is that the search according to the ID of ground objects is often carried out (including searching the corresponding records from the given ground objects, but also retrieving the corresponding ground features according to the given ground records), which slows down the speed of some operations such as query, model operation and so on.
(a)通过文件管理空间数据
(b)通过关系数据库管理属性数据
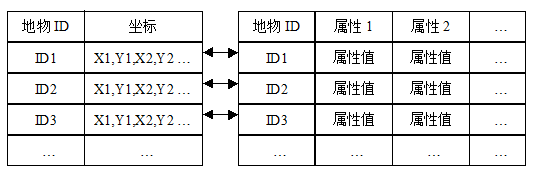
Figure 16-11: managing GIS data using both file and relational databases
Among them, the connection between records is established by using figure ID.
All are managed by relational database.
In this management mode, the coordinate data of spatial geometry with variable length is managed by the relational database in the form of binary data blocks, in other words, the coordinate data is integrated into RDBMS to form a spatial database, whose structure is shown in figure 16-12.
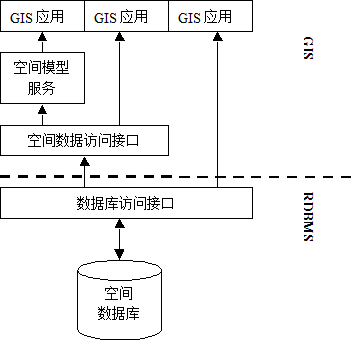
Figure 16-12: integrated GIS data management
It can be considered that a figure corresponds to a record in the data table, so the most direct benefit it brings is that it avoids the search for “join relationships”. At present, relational databases have become mature both in theory and tools. They provide consistent access interface (SQL) to manipulate distributed massive data, and support multi-user concurrent access, security control and consistency checking. These are exactly what is needed to construct an enterprise-level geographic information system. In addition, the general access interface is also convenient to realize data sharing.
Using full-relational GIS data management, due to the variable length of geometry coordinate data, the storage efficiency will be inefficient. In addition, the existing SQL does not support spatial data retrieval, so it is necessary for software manufacturers to develop spatial data access interfaces. If they want to support spatial data sharing, SQL should be extended.
Using object-oriented database (OO-DBMS) to manage
If the object database is used to manage GIS data, the data types in the object database can be expanded to support spatial data, including points, lines, polygons and other geometry, and allow the definition of basic operations for these geometry, including calculating distances, detecting spatial relationships, and even slightly complex operations, such as buffer calculation, superimposed composite model, etc., which can also be “seamlessly” supported by the object database management system.
In this way, through the object database management system, it provides a consistent access interface for all kinds of data and some spatial model services, which not only realizes data sharing, but also spatial model services can be shared, so that GIS software development can focus on data representation and complex professional models (figure 16-13).
However, the current object database management system is far from mature, and many technical problems still need to be further studied. For example, a malicious intrusion into the system may be triggered by the support of user-defined features. Query optimization is also a difficult problem faced by the object database. Assuming that all the counties with railways passing through and with a population of more than 100000 are to be queried, it is obvious that the computing time required to get counties with a population greater than 100000 is much less than that for counties with all railways. The system must understand this and first get the counties with a population greater than 100000 when performing the query. Then make a further search in the collection based on spatial relationships– regardless of the actual input order of the user. This process is called query optimization (Optimize), which reduces the computing time after optimization. For this simple case, that is, the time consuming of structured query and spatial operation, it is easy to compare and judge, but if multiple spatial operation functions are included in the query statement, then its optimization will become very difficult.
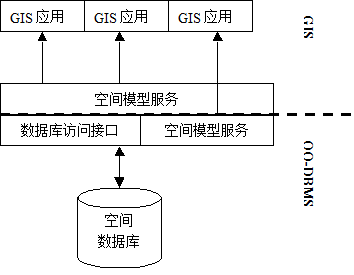
Figure 16-13: GIS data management using OO-DBMS