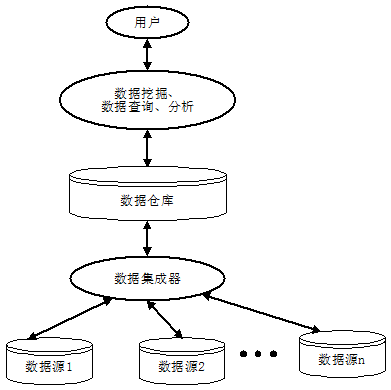
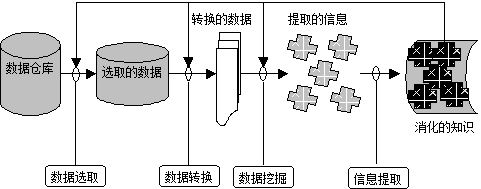
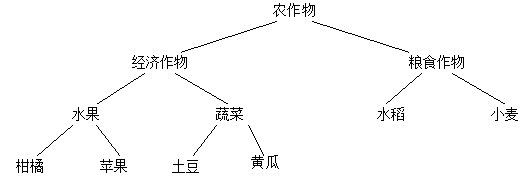
With the increasing use of satellite and remote sensing technologies and other automated data collection tools, increasingly abundant spatial and non-spatial data is collected and stored in large spatial databases, and massive geographic data has surpassed people to some extent, the ability to process, extract and discover geoscience knowledge from these massive data presents a huge challenge to current GIS technologies. The new demand drives the transition of GIS from operational information system to analytical information system, the latest data warehouse and database knowledge discovery technology of database system provides new ideas for GIS organization and management of massive space and non-spatial data. The ability of GIS to store, express and manage spatial data has been widely recognized, enhance GIS analysis and improve GIS’s practical problems in geosciences has been recognized. GIS absorbs the idea of data warehouse, tightly integrates spatial analysis and spatial data mining methods, makes full use of GIS data storage and manages spatial data functions, and makes massive geospatial data become infinite knowledge, making GIS an intelligent information system. In recent years, people have come to realize that there are two different types of processing in computer systems: operational processing and analytical processing. Operational processing, also known as transactional processing, refers to the daily operation of the database online, usually querying and modifying a record or a group of records, mainly serving enterprise-specific applications, people are concerned about response time, data security and integrity. Analytical processing is used for decision analysis of managers, such as decision support system, expert system and multi-dimensional analysis, which often accesses a large number of historical data. The huge difference between the two makes the separation of operational and analytical processing inevitable, so the database has developed from an operational environment to a new systematic environment of operational and analytical environments. In this new system environment, data warehouse is the core, which is the basis of establishing decision support system. A data warehouse is a topic-oriented, integrated, stable, time-varying collection of data to support management decisions. This definition points out that the goal of the data warehouse is to provide support information for making management decisions. Just as enterprises need to reorganize their business in order to support management decision-making, they also need to reorganize the data in the online transaction processing (OLTP) system according to the requirements of the decision-making business subject, and organize the analysis contents according to different decisions. In other words, data warehousing is a way to turn collected data into meaningful information technology, data can come from many different data sources, including different database systems, and even from different operating systems. Fig. 159 Data Warehouse Architecture # Before the data is loaded into the data warehouse after the data structure is reorganized, data integration processing is required. This process includes several essential steps to make the data complete and uniform, which ensures that the data is quality assured when using the data warehouse. In short, integration is to ensure that the data is accurate, in place, does not exceed the range of values that should be, and there is no duplication. The data in the data warehouse is not as modified as the data in the online transaction processing system, so it is relatively stable (with little or no modification). The data used during the execution of a data analysis must not be changed to ensure that two different answers are not used when analyzing the same set of information. A data warehouse typically periodically updates data from an online transaction processing system on a weekly, monthly, or monthly basis. A typical data warehouse architecture is shown in Figure 10-12, data is extracted from multiple operational databases and external files, the extracted data is cleaned, transformed, and integrated, and then loaded into the data warehouse.The form of data loaded into the warehouse depends on the design of the database in the data warehouse. The general data warehouse design method is a multidimensional data model, which is expressed in star mode or snowflake mode. The warehouse data is updated regularly to reflect changes in the source data. Finally, use front-end tools such as reporting, querying, analysis, and data mining to manipulate and use the data warehouse. In terms of data warehouse management, there is a central database or data dictionary that stores metadata (data about warehouse data), and monitoring and management tools are also essential. With the rapid growth of a large number of large-scale databases, people’s application of the database is not satisfied with querying and retrieving only the database. Searching with queries alone does not help users extract useful and conclusive information from the data. Such rich knowledge in the database will not be fully explored and utilized, resulting in the phenomenon of “rich data and poor knowledge”. In addition, from the perspective of artificial intelligence applications, the research of expert systems has made some progress. However, knowledge acquisition is still the bottleneck in the research of expert systems. Knowledge engineers’ acquisition of knowledge from domain experts is a very complex process of interaction between individuals and individuals. It has a strong personality and there is no uniform approach. Therefore, it is necessary to consider discovering new knowledge from the database, known as Knowledge Discovery in Databases (KDD), also known as Data Mining. Database knowledge discovery or data mining is defined as the process of extracting implicit, previously unknown, and potentially useful knowledge from data. Data mining technology integrates the latest technologies in machine learning, database systems, data visualization, statistics and information theory, and has broad application prospects. Data mining is divided into the following four steps: 1) Data selection The data in data warehouse is not all related to the information mined, the first step is to extract only “useful” data. 2) Data conversion After determining the data to be mined, the necessary transformations are needed to make the data available for further operation, the usual transformations are: In order to facilitate the operation of artificial neural network, the nominal quantities are converted into sequential quantities; Mathematical or logical operations are performed on existing attributes to create new attributes. 3) Data mining After data conversion, data mining is necessary. There are many specific technologies of data mining, such as classification, regression analysis and so on. 4) Interpretation of results The mined information is analyzed with reference to the user’s decision support objectives and is presented to the decision maker. In this way, the output of the result contains not only the process of visualization, but also filtering to remove content that the decision maker does not care about. After performing a mining process, sometimes it may be necessary to re-modify the mining process, and other data may be added, the data mining process can be repeated by appropriate feedback, as shown in Figure 10-13. Fig. 160 Knowledge mining process # There are many subject areas and methods involved in data mining, and there are many classification methods. According to the knowledge discovery task, it can be divided into classification or prediction model discovery, data summary, clustering, association rule discovery, sequence pattern discovery, dependency or dependency model discovery, exception and trend discovery, etc. According to the knowledge discovery object, it can be divided into relational database, object-oriented database, spatial database, time database, text data source, multimedia database, heterogeneous database, and Web database; according to the knowledge discovery method, which can be roughly divided into machine learning method, statistical method, neural network method and database method. In machine learning, it can be subdivided into inductive learning methods (decision trees, rule induction, etc.), case-based learning, genetic algorithms, etc. Statistical methods can be subdivided into regression analysis (multivariate regression, autoregressive, etc.), discriminant analysis (Bayesian discriminant, Fisher discriminant, nonparametric discriminant, etc.), cluster analysis (system clustering, dynamic clustering, etc.) ), exploratory analysis (principal element analysis, correlation analysis, etc.). In the neural network method, it can be subdivided into a forward neural network (BP algorithm, etc.), a self-organizing neural network (self-organizing feature mapping, competitive learning, etc.). Database methods are mainly multidimensional data analysis or online transaction processing methods, in addition to attribute-oriented induction methods. Spatial data is data related to objects occupying a certain space, spatial databases store and manage spatial data through spatial data types and spatial relationships. Spatial data typically has topology and distance information that is organized and queried through spatial indexes. The unique nature of spatial data presents challenges and opportunities for knowledge discovery in spatial databases. Knowledge discovery or spatial data mining of spatial databases can be defined as the process of extracting implicit knowledge from spatial databases and spatial relationships and spatial patterns without direct storage. Spatial data mining technology, especially spatial data understanding, spatial and non-spatial data relationship discovery, spatial knowledge base construction, spatial database query optimization and data organization, has great prospects in GIS, remote sensing, image database, robot motion and other applications involving spatial data. Following is a brief introduction to some of the methods currently used in spatial data mining: 1) Statistical analysis method At present, the most commonly used method of spatial data analysis is statistical analysis. Statistical analysis is very suitable for processing numerical data. Statistical analysis methods have accumulated a large number of algorithms over the years, which can be used to model and analyze spatial phenomena. However, spatial statistical analysis also has great shortcomings: firstly, the assumption of statistical independence of spatial distribution data in statistical analysis methods is often unrealistic, because there is a relationship between spatial neighborhoods; secondly, statistical analysis is not suitable for dealing with non-numerical data, such as the name of spatial objects and the type of named data. In addition, statistical analysis often requires high knowledge of domain experts and statistics, which is only suitable for the use of domain experts and people with statistical experience, and when the data are incomplete or insufficient, the results of statistical analysis lack practical significance. Moreover, the computational cost of statistical analysis is very high. In order to overcome the shortcomings of statistical analysis methods, new data mining methods are needed. 2) Based on a generalized approach Generalization-based method is an attribute-oriented inductive learning method for spatial data mining, which can generalize the relationship between spatial and non-spatial attributes into high-level conceptual knowledge. It needs background knowledge, namely Concept Hierarchy, which is often given in the form of concept tree. Fig. 10-14 shows a concept tree of agricultural land use. Similarly, spatial data also have similar conceptual levels, such as township-county-province-country. Attribute-oriented inductive learning method obtains generalized data by climbing concept tree. The generalized data can be directly transformed into rules or logical expressions, and can be used to discover universal feature rules and zoning rules. Inductive learning of spatial databases can be based on the conceptual level of non-spatial data or the conceptual level of describing spatial data. Based on conceptual hierarchy induction of non-spatial data, such as numerical data can be grouped into a numerical range or a higher-level conceptual descriptive variable (-9 ℃ within the range of -10 ℃ to 0 ℃, or “cold”), which can be generalized into higher-level identical data through lower-level data with different values, which are merged together by data of different tuples and their spatial object pointers. High-level data, representing a new spatial attribute. Conceptual hierarchy induction based on spatial data can be defined by zoning or spatial storage structures such as quadtree. Fig. 161 Summary Example # Generally, there are two methods based on generalization: non-spatial data generalization and spatial data generalization. The first step of these two algorithms is to select user-specific query data. Next, non-spatial data-based generalization algorithm process is: (A) concept tree climbing, that is, tuple attributes into high-level attributes; (B) attribute deletion, deletion of those special attributes that can not be generalized; (C) the combination of identified tuple. The induction process lasts until all attributes are generalized to the appropriate level. Finally, the adjacent regions with the same attributes are merged, resulting in a graph with higher conceptual level and fewer regions. The first step is to collect the data queried by users, and then merge the spatial objects according to the given conceptual hierarchy of spatial data. The generalization process lasts until the required conceptual hierarchy is reached. Then the non-spatial data is generalized for each generalized spatial object until all regions are correctly described. 3) Clustering method Clustering analysis is a branch of statistical analysis. The main advantage of this method is that it does not need background knowledge and can directly find interested structures or clustering patterns from data, similar to unsupervised learning in machine learning. The combination of clustering analysis and attribute-oriented inductive reasoning makes it possible to describe the spatial behavior of similar objects, or to determine the characteristics of different categories. It can also be divided into two methods: spatial data-based and non-spatial data-based. Spatial data is the main method. Firstly, task-related spatial objects (such as points) are classified by efficient clustering algorithm based on sampling. Then, attribute-oriented inductive reasoning is used to extract and describe various general attributes from non-spatial data. In the non-spatial data-based method, the task-related spatial objects are generalized to a higher conceptual level, clustering analysis is carried out, and then the spatial objects are merged. 4) Spatial association rule method Association rules are derived from the discovery of implicit interdependence among commodities in transaction data sets. If a rule is found in the supermarket database in the form of “WB (C%)”, the meaning of the rule is “If W mode appears in the transaction, there is a possibility that C% will appear in B mode (credibility). For example, the rule “milk butter (90%)” indicates that 90% of milk buyers will buy butter at the same time. This is the association rule. It can also be used to discover spatial relationships. Spatial association rules take the form of: At least one of the predicates is a spatial predicate; C% is the reliability of association rules. There are many forms of spatial predicates to construct spatial association rules, such as topological relations (intersection, inclusion, overlap, etc.), orientation relations (left, west, etc.), distance relations (proximity, distance, etc.). Association rules can usually be divided into two types: Boolean association rules and multivalued Association rules. Multivalued association rules are complex. A natural idea is to transform them into Boolean Association rules. When the number of values of all attributes is limited, it is only necessary to map each attribute value to a Boolean attribute. When the range of attribute values is very wide, it needs to be divided into several segments, and then each segment is mapped to a Boolean attribute. Therefore, how to divide sections is the key to realize the transformation from multi-valued association rules to Boolean Association rules. There are two interdependent problems: when the range of segments is too narrow, the support degree of attributes corresponding to each segment may be very low, and the problem of “minimum support degree” may arise; when the range of segments is too wide, the reliability of attributes corresponding to each segment may be very low, and the problem of “minimum confidence degree” may arise. In a set S, the support of a spatial join predicate is the ratio of the number of objects satisfying P to the total number of objects in S; the confidence of the association rule PQ in set S. The discovery of association rules can be decomposed into the following two sub-problems: (4.1) Find out all object sets P (a non-empty subset) in database S that satisfy the user specified minimum support. The object sets with minimum support are called frequent object sets, and vice versa, infrequent object sets. (4.2) Generate association rules using frequent object sets. For each frequent object set P, find out all non-empty subsets Q of P, and generate association rules PQ if the ratio /≥ minimum confidence. Following is a brief introduction to the algorithm process of spatial association rules: Input: spatial database, mining query, association constraint set The database includes three parts: the spatial database containing spatial objects, the relational database describing non-spatial information, and the conceptual hierarchy set; The query also includes three parts: the object class S to be described, the space object subclass There are three constraints: the minimum support, the minimum credibility and the maximum distance to satisfy the “near” spatial predicate at each conceptual level. Output: Strong spatial association rules at multiple conceptual levels for objects Methods: The computational procedures for spatial association discovery were as follows: Layer 1 for generating subclasses of associated objects; All the subclass objects Layer 2 for generating subclasses of associated objects; Generate a predicate that acts on the object Add the predicate of the object Search for spatial association rules with high reliability in predicate database. Spatial predicates exist in an extended relational database—in the predicate database, the attribute values are single-valued or multi-valued sets. A record of the predicate database describes the relationship between an object Data Warehouse #
Data Mining #
Spatial data mining #
C_1
, …
C_n
related to the task, the related relationship and the predicate set;
Ci
of the related objects are processed as follows at the same time:
C_i
(as layer 1 intersects layer 2, given the distance condition);
C_i
to the predicate database.
S_i
in the object class S and the object
C_j
that satisfies the predicate relationship.